Benchmaxxing Series: Bootstrapping for Meaningless Confidence Intervals
evaluation
Author
cstorm125
Published
July 28, 2026
This series document statistical tomfooleries in AI evaluation that I may or may not have witnessed from “academic researches” and “technical works” in the wild. For educational purposes only. All characters appearing in this work are fictions. Any resemblance to real persons, living or dead, is purely coincidental. Do not try this at home.
Background on Benchmaxxing in the Finetuning Game
Statistical robustness has taken somewhat of a back seat in modern LLM evaluation, and perhaps reasonably so. Frontier benchmarks such as SWE-Bench and GDPEval often start near 0% then subsequently jump with new model iterations; for example, 9.9%→30.8% from GPT-4o to o3 medium on GDPEval. We do not need a hypothesis test to tell us that these uplifts are statistically significant at p-value = 0.0000.... Nonetheless, in the shadow of corporate juggernauts vying for foundational model supremacy, the 2nd/3rd-tier players are engaged in more incremental improvements (0.5-1%), one of which is localizing frontier models.
Figure 1: GDPEval needs no hypothesis testing (Left); Yours truly is also not totally innocent about reporting only point estimates (Right)1
The playbook usually goes like this:
Take an open-source, frontier model from a Chinese lab of your choice (Qwen, Deepseek, Kimi, GLM, MiniMax, etc.).
Finetune it on your language and/or domain.
Test on a self-made/curated local benchmark to show 0.5-1% improvement on the base model.
Profit💲💲; literally, as most of these 2nd/3rd-tier players either live off of government funding under the guise of “protecting AI sovereignty”2 or are trying to convince stakeholders in their domains (usually finance and medical) that their finetuning activities have some value-added, however marginally.
I am all good about people trying to make a living, but this playbook has spawned some undesirable behaviors in AI system evaluation. By nature of these localization projects, the benchmarks are limited in quantity (the most sloppy one I have seen has as few as 100 multiple-choice questions per task), quality (multiple-choice college entrance exams may be tough for BERT in 2018 but meaningless for post-GPT3 LLMs; most benchmarks are curated by the same teams finetuning the models without any rigorous independent oversight with no transparency on splits), and most importantly the ability to distinguish between a successful finetuning and statistical noise. Unlike in the case of frontier models where the leap of progress is enormous, claiming success on 0.5-1% difference in point estimates is at best naive and at most unscrupulous. This is especially relevant since these claims could lead to approval of multi-million-USD funding in taxpayer’s money.
This article explains with a synthetic dataset how “researchers” may misdirect their audience with seemingly sophisticated bootstrapped confidence intervals to appear as though there is statistical significance where there is none, a la cargo cult science described by late Richard Feynman.
The Synthetic Setup
Comparing point estimates might warrant the benefit of the doubt, but artificially manipulating the confidence intervals by abusing bootstrapping, both conceptually AND mathematically, certainly does not.
Let us see this in action using a synthetic example of a classification-style benchmark3 with 4,000 questions. We apply the parameters and procedures similar to an actual localization project. We compare a base model A, a finetuned model that failed B (0pp true uplift in performance), and one that succeeded C (+1pp true uplift in performance). Each model predicts a binary or multiple-choice answer to each question and is scored on accuracy. First, we need a generative process that mirrors what LLM evaluations actually look like. A few empirical anchors shape the setup:
Overall accuracy lands around 57% across the 4,000 questions for model A. This is roughly where mid-sized models score on a reasonably difficult multi-language benchmark.
Answer consistency across runs is high.Cavalin et al. (2025) report that medium-sized models like Llama-3.3-70B give the same answer to the same question in 96–98% of repetitions on MMLU at low temperature, with per-run accuracy standard deviations as low as 0.1pp. A ~32B model at low temperature should live in a similar regime on pure MMLU-style tasks, but aggregated multi-task benchmarks typically mix in higher-variance metrics such as ROUGE and win-rate, which pull effective consistency down. We target ~87% pairwise answer consistency so that methods below match reported confidence intervals in the wild.
To simulate decoding stochasticity between runs, we draw each question’s latent probability of being answered correctly, \(p_q\), from a three-component mixture: a fraction of “easy” questions the model always gets right (\(p_q = 1\)), a fraction of “hard” questions it always gets wrong (\(p_q = 0\)), and a “middle” fraction where \(p_q \sim \text{Uniform}(0.2, 0.8)\).
Each independent run for each question is then an independent draw from \(\text{Bernoulli}(p_q)\). Crucially, B and C inherit A’s latent per-question difficulty where B is a clone of A (identical true accuracy, same difficulty profile), and C promotes 1% of A’s “hard” questions into “easy” ones for a clean +1pp uplift. This mirrors how a finetune of a base model typically shares most of its correct/incorrect behavior with the base and differs on only a small fraction of questions.
Below are mean observed accuracies, per-run standard deviations and pairwise consistency (how many percentage of 4,000 answers are the same on average) across 8 simulated runs.
Code
import numpy as npimport pandas as pdfrom scipy import statsfrom plotnine import ( ggplot, aes, geom_point, geom_errorbarh, facet_wrap, labs, theme_bw, theme, element_text, scale_color_brewer,)SEED =20260504N_QUESTIONS =4000N_RUNS =8Z =1.96A_EASY, A_HARD =0.420, 0.280UPLIFT =0.01# +1pp true uplift for model Cdef sample_p_q(n: int, pi_easy: float, pi_hard: float, rng: np.random.Generator) -> np.ndarray:"""Draw per-question true success probabilities from the 3-mixture.""" u = rng.random(n)return np.where( u < pi_easy, 1.0, np.where(u < pi_easy + pi_hard, 0.0, rng.uniform(0.2, 0.8, size=n)), )def derive_finetune(p_base: np.ndarray, uplift: float, rng: np.random.Generator) -> np.ndarray:"""Promote a random `uplift` fraction of base's hard questions (p=0) to easy (p=1). Every other question is unchanged, so the finetune shares latent difficulty with the base on (1 - uplift) of the benchmark — the realistic regime for a finetune.""" p = p_base.copy() hard_idx = np.where(p_base ==0.0)[0] n_promote =int(round(uplift *len(p_base))) p[rng.choice(hard_idx, size=n_promote, replace=False)] =1.0return pdef simulate_runs(p_q: np.ndarray, n_runs: int, rng: np.random.Generator) -> np.ndarray:"""Draw n_runs x n_q independent Bernoulli(p_q) scores."""return (rng.random((n_runs, len(p_q))) < p_q).astype(int)def pairwise_consistency(s: np.ndarray) ->float:"""Fraction of (run_i, run_j) pairs per question that agree, averaged over questions.""" n_runs, n_q = s.shape agree = total =0for i inrange(n_runs):for j inrange(i +1, n_runs): agree += (s[i] == s[j]).sum() total += n_qreturn agree / totalrng = np.random.default_rng(SEED)p_A = sample_p_q(N_QUESTIONS, A_EASY, A_HARD, rng)p_B = p_A.copy() # failed finetune: identical to Ap_C = derive_finetune(p_A, UPLIFT, rng) # successful finetune: +1pp true upliftp_truth = {"A": p_A, "B": p_B, "C": p_C}scores = {name: simulate_runs(p, N_RUNS, rng) for name, p in p_truth.items()}for name, s in scores.items(): acc_per_run = s.mean(axis=1)print(f"Model {name}: true acc {p_truth[name].mean()*100:.2f}%, "f"obs acc {acc_per_run.mean()*100:.2f}%, "f"per-run stdev {acc_per_run.std(ddof=1)*100:.3f}pp, "f"pairwise consistency {pairwise_consistency(s)*100:.1f}%" )
Before reaching for any bootstrap machinery, let us ask the simpler question: if we ran each model once on the same 4,000 questions and applied a proper test, could we detect a 1pp uplift?
The test for binary-scored paired data is McNemar’s test4. It looks at the questions where the two models disagreed, called discordant pairs, and asks whether the disagreements lean systematically one way. Questions where both models got the same answer cancel out of the difference, so they contribute nothing to the test statistic, which is exactly why pairing gives tighter confidence intervals than treating the two runs as independent samples. For the single-run case with \(n_{01}\) questions where B beat A and \(n_{10}\) questions where A beat B, the observed difference in accuracies is \(\hat{\delta} = (n_{01} - n_{10})/n\) with standard error \(\text{SE}(\hat{\delta}) = \sqrt{(n_{01} + n_{10})/n^2}\).
Code
def mcnemar_test(x: np.ndarray, y: np.ndarray) ->dict:"""Paired test on single-run binary scores; returns diff, SE, 95% CI, z, p. Implementation note. The textbook McNemar's statistic is chi-squared: chi2 = (n01 - n10)**2 / (n01 + n10), df=1 We use the algebraically equivalent z-form z = (n01 - n10) / sqrt(n01 + n10), which satisfies z**2 = chi2 and produces identical two-sided p-values under the normal approximation (sanity-checked against statsmodels in the appendix). The z-form is preferred here because we also need a directional SE on the accuracy difference in order to build the CI used in the plots. """ n10 =int(((x ==1) & (y ==0)).sum()) # x right, y wrong n01 =int(((x ==0) & (y ==1)).sum()) # x wrong, y right n =len(x) diff = (y.mean() - x.mean()) *100 se = np.sqrt(n10 + n01) / n *100 z = diff / se if se >0else0.0 p =2* (1- stats.norm.cdf(abs(z)))return {"diff": diff, "se": se, "ci95": Z * se, "z": z, "p": p, "n10": n10, "n01": n01}# One run per model: the honest cheap comparison.a0, b0, c0 = scores["A"][0], scores["B"][0], scores["C"][0]rows = []for label, x, y in [("A vs B (true diff = 0)", a0, b0), ("A vs C (true diff = +1pp)", a0, c0)]: r = mcnemar_test(x, y) rows.append({"comparison": label,"obs diff": f"{r['diff']:+.2f}pp","95% CI on diff": f"±{r['ci95']:.2f}pp","z": f"{r['z']:.2f}","p-value": f"{r['p']:.3f}", })pd.DataFrame(rows)
comparison
obs diff
95% CI on diff
z
p-value
0
A vs B (true diff = 0)
+0.92pp
±1.11pp
1.64
0.101
1
A vs C (true diff = +1pp)
+2.05pp
±1.16pp
3.47
0.001
In this particular simulation the 1pp uplift (A-vs-C) lands at z = 3.47 with p = 0.001, which looks convincing. But that is a single draw of the benchmark. With a different seed, the observed gap will land somewhere else, and that somewhere-else determines whether the test rejects the null or not. To build intuition, let us repeat the single-run comparison five times with different seeds and see what happens.
Code
trial_rows = []for trial inrange(5): trial_rng = np.random.default_rng(SEED + trial *997) p_A_t = sample_p_q(N_QUESTIONS, A_EASY, A_HARD, trial_rng) p_B_t = p_A_t.copy() p_C_t = derive_finetune(p_A_t, UPLIFT, trial_rng) a1 = (trial_rng.random((1, N_QUESTIONS)) < p_A_t).astype(int)[0] b1 = (trial_rng.random((1, N_QUESTIONS)) < p_B_t).astype(int)[0] c1 = (trial_rng.random((1, N_QUESTIONS)) < p_C_t).astype(int)[0] r_AB = mcnemar_test(a1, b1) r_AC = mcnemar_test(a1, c1) trial_rows.append({"trial": trial +1,"A vs B obs diff": f"{r_AB['diff']:+.2f}pp","A vs B p-value": f"{r_AB['p']:.3f}","A vs B verdict": "false positive"if r_AB["p"] <0.05else"correctly ns","A vs C obs diff": f"{r_AC['diff']:+.2f}pp","A vs C p-value": f"{r_AC['p']:.3f}","A vs C verdict": "detected"if r_AC["p"] <0.05else"missed", })pd.DataFrame(trial_rows)
trial
A vs B obs diff
A vs B p-value
A vs B verdict
A vs C obs diff
A vs C p-value
A vs C verdict
0
1
+0.18pp
0.764
correctly ns
+2.08pp
0.001
detected
1
2
+0.35pp
0.546
correctly ns
+1.95pp
0.001
detected
2
3
+0.13pp
0.826
correctly ns
+0.48pp
0.425
missed
3
4
+0.28pp
0.649
correctly ns
+1.12pp
0.070
missed
4
5
-0.02pp
0.966
correctly ns
+0.92pp
0.118
missed
Look at what happened. On the A-vs-B comparison (the two models are identical, true difference = 0), all five trials gave non-significant p-values; no false positives, which is what a calibrated 5% test should deliver most of the time. The observed differences bounced around ±0.3pp from pure decoding noise, but they stayed within the ±1.1pp McNemar’s band so nothing looked like a win.
The A-vs-C comparison is more interesting. Only 2 of the 5 trials rejected the null at p < 0.05. Trials 1 and 2 happened to catch the +1pp effect, but they overshot; the observed differences were +2.08pp and +1.95pp, roughly twice the true effect, inflated by favorable decoding noise. Trial 3 undershot to +0.48pp and missed entirely (p = 0.43). Trials 4 and 5 landed close to the true +1pp effect but just short of the p<0.05 threshold.
This is how statistical power works in practice. In this particular case, the signal you are trying to detect is buried in enough noise that you see it clearly only about 40% of the time, even with the correct test. This is not a failing of the McNemar’s test; 4,000 questions is simply too few detect 1pp uplift reliably. No amount of statistical cleverness will change that fundamental limit. This is the uncomfortable truth that drives people toward bootstrap shenanigans.
Code
E_u_1_minus_u =0.5-0.28# E[U(1-U)] for U ~ Uniform(0.2, 0.8)p_middle =1- A_EASY - A_HARD # middle-bucket sharep_noise_discord = p_middle * E_u_1_minus_u # per-q one-direction discord from decoding noise# Promotion moves questions from hard (p=0) to easy (p=1), so middle contributes to# decoding-noise discord on ALL questions (not just (1 - UPLIFT) of them). Promoted# questions add a deterministic contribution of UPLIFT to p_01.p_01 = p_noise_discord + UPLIFT *1.0p_10 = p_noise_discord + UPLIFT *0.0pi_D = p_01 + p_10 # expected total discordance ratedelta = p_01 - p_10 # expected signed difference per question# Under the alternative, z ≈ δ·sqrt(n / π_D); power follows from the normal approximation.z_H1 = delta * np.sqrt(N_QUESTIONS / pi_D)mcnemar_power = stats.norm.cdf(z_H1 - Z) + stats.norm.cdf(-z_H1 - Z)print(f"Expected discordance rate π_D: {pi_D*100:.1f}% (of 4,000 questions)")print(f"Expected signed difference δ: {delta*100:+.2f}pp")print(f"Expected z under H1: {z_H1:.2f}")print(f"Analytical power of McNemar's test to detect +1pp uplift: {mcnemar_power*100:.1f}%")# Empirical power: simulate many single-run A-vs-C comparisons and count rejections.N_POWER_SIMS =2000rejections =0power_rng = np.random.default_rng(SEED +42)for _ inrange(N_POWER_SIMS): p_A_sim = sample_p_q(N_QUESTIONS, A_EASY, A_HARD, power_rng) p_C_sim = derive_finetune(p_A_sim, UPLIFT, power_rng) a_sim = (power_rng.random(N_QUESTIONS) < p_A_sim).astype(int) c_sim = (power_rng.random(N_QUESTIONS) < p_C_sim).astype(int)if mcnemar_test(a_sim, c_sim)["p"] <0.05: rejections +=1print(f"Empirical power over {N_POWER_SIMS} simulated benchmarks: {rejections / N_POWER_SIMS *100:.1f}%")
Expected discordance rate π_D: 14.2% (of 4,000 questions)
Expected signed difference δ: +1.00pp
Expected z under H1: 1.68
Analytical power of McNemar's test to detect +1pp uplift: 38.9%
Empirical power over 2000 simulated benchmarks: 37.8%
Dishonest Bootstrapping: Conceptually and Mathematically
With a 1pp effect sitting at ~40% single-run detection power, the temptation is obvious: pad the story with more statistical smoke and mirrors until the CI looks small. This is where bootstrap procedures start creeping into localization papers. Instead of running a McNemar’s test once and gambling your multi-million government contract with worse odds than a coin flip, why not run it 8 times (just small enough to cherry-pick) and bootstrap (sample with replacement) each question’s answer for 30 hypothetical runs? If you have any exposure to Introduction to Statisticsーor I do not know, common senseーyou would intuitively question how one can infer variations from just 8 independent runs, no matter how many times they re-sample with replacement.
We walk through three, increasingly more degenerate bootstrap flavors below, each introducing one more shortcut that shrinks the CI without actually adding information. To make the visual differences obvious, we pick a seed5 where the narrowest method happens to land in its failure mode, one of the parallel-universe benchmarks where it flags the failed finetune model B as significantly different from A even though the two models are structurally identical. This is not to cherry-pick to be unfair; the 2000-simulation calibration in the later section confirms that ~40% is the method’s typical false-positive rate (poetically trading off 40% power for 40% false positive rate), not an edge case.
Code
DISPLAY_SEED =20260508display_rng = np.random.default_rng(DISPLAY_SEED)p_A_d = sample_p_q(N_QUESTIONS, A_EASY, A_HARD, display_rng)p_B_d = p_A_d.copy()p_C_d = derive_finetune(p_A_d, UPLIFT, display_rng)p_truth_d = {"B": p_B_d, "A": p_A_d, "C": p_C_d}scores_d = {name: simulate_runs(p, N_RUNS, display_rng) for name, p in p_truth_d.items()}for name in ["A", "B", "C"]: s = scores_d[name] acc = s.mean(axis=1)print(f"Display seed model {name}: true {p_truth_d[name].mean()*100:.2f}%, "f"obs {acc.mean()*100:.2f}%, per-run stdev {acc.std(ddof=1)*100:.3f}pp")
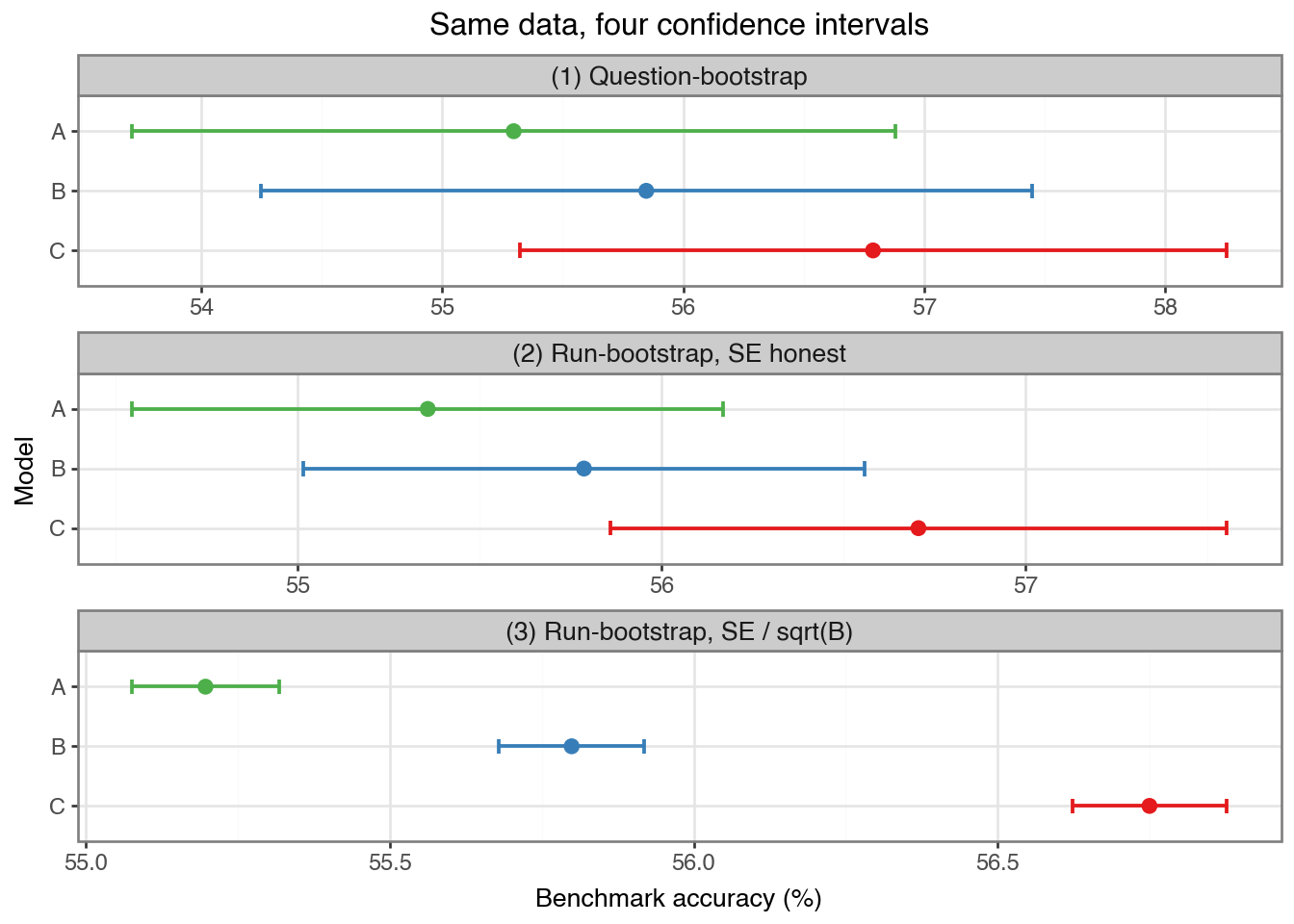
N_BOOTSTRAPS =30# same B across all bootstrap flavors belowdef ci_question_bootstrap(s: np.ndarray, rng: np.random.Generator) ->tuple[float, float, float]:"""(1) Question-bootstrap: resample questions with replacement; per-question score = mean of 8 runs. The only method that captures question-sampling variability.""" per_q_score = s.mean(axis=0) n_q =len(per_q_score) idx = rng.integers(0, n_q, size=(N_BOOTSTRAPS, n_q)) replicate_acc = per_q_score[idx].mean(axis=1) mean = per_q_score.mean() se = replicate_acc.std(ddof=1)return mean, mean - Z * se, mean + Z * sedef ci_run_bootstrap_fixed(s: np.ndarray, rng: np.random.Generator) ->tuple[float, float, float]:"""(2) Run-bootstrap with honest SE = stdev(replicates). Resamples runs instead of questions, so it measures only decoding noise, not question-sampling variability.""" n_runs, n_q = s.shape idx = rng.integers(0, n_runs, size=(N_BOOTSTRAPS, n_q)) replicate_acc = s[idx, np.arange(n_q)].mean(axis=1) mean = replicate_acc.mean() se = replicate_acc.std(ddof=1)return mean, mean - Z * se, mean + Z * sedef ci_run_bootstrap_sqrt_b(s: np.ndarray, rng: np.random.Generator) ->tuple[float, float, float]:"""(3) Run-bootstrap with SE = stdev(replicates) / sqrt(B). The method in the wild. Numerator is an 8-run average; denominator pretends to be the SE of a 30-run average.""" n_runs, n_q = s.shape idx = rng.integers(0, n_runs, size=(N_BOOTSTRAPS, n_q)) replicate_acc = s[idx, np.arange(n_q)].mean(axis=1) mean = replicate_acc.mean() se = replicate_acc.std(ddof=1) / np.sqrt(N_BOOTSTRAPS)return mean, mean - Z * se, mean + Z * serows = []method_order = ["(1) Question-bootstrap","(2) Run-bootstrap, SE honest","(3) Run-bootstrap, SE / sqrt(B)",]method_fns = { method_order[0]: ci_question_bootstrap, method_order[1]: ci_run_bootstrap_fixed, method_order[2]: ci_run_bootstrap_sqrt_b,}for m_idx, name inenumerate(["A", "B", "C"]): s = scores_d[name]for k_idx, method inenumerate(method_order):# Deterministic per-(model, method) seed so the plot is stable across runs. rng_m = np.random.default_rng(DISPLAY_SEED +1000* m_idx + k_idx) m, lo, hi = method_fns[method](s, rng_m) rows.append({"model": name,"method": method,"mean": m *100,"lo": lo *100,"hi": hi *100,"half_width": (hi - m) *100, })ci_df = pd.DataFrame(rows)ci_df["± (95% CI)"] = ci_df["half_width"].map(lambda x: f"±{x:.2f}")ci_df["accuracy"] = ci_df["mean"].map(lambda x: f"{x:.2f}%")display_df = ci_df.pivot(index="method", columns="model", values=["accuracy", "± (95% CI)"])display_df = display_df.reindex(method_order)display_df
Method 1): question-bootstrap. We resample questions with replacement, using the mean of 8 runs as each question’s score. The resampling directly simulates drawing a different 4,000-question benchmark from the same distribution, which is exactly the uncertainty we care about when we claim “the finetune is better on XX language/domain”. The CI lands around ±1pp on single-model accuracy. A, B, and C overlap heavily, which correctly reflects that a single-model absolute accuracy CI cannot resolve a 1pp difference. However, this method is at least conceptually honest in what it is trying to detect.
Method 2): run-bootstrap with honest SE. Instead of resampling questions, we resample the 8 runs per question: for every bootstrap replicate, each question independently picks one of its 8 observed answers, and the replicate’s accuracy is the mean of those 4,000 picks. This produces a distribution of “what accuracy would we have gotten on these same 4,000 questions if we had drawn a different decoding seed?” Note the weirdness baked into the procedure already, Frankenstein run whose question 17 comes from seed 3 and question 42 comes from seed 7, but this is exactly the recipe that shows up in the wild, so we faithfully reproduce it.
Now, I would like readers to pause here for a second and think about if we really care about decoding noise so much we would need to engage in this statistical wizardry; the answer is most likely no. So even without validating its mathematical rigor, this method is conceptually dishonest. But people who are trying to advertise this as a legitimate method either wants you to think so or hopes you would confuse this with what method 1) is trying to do.
Because 87%-consistent models give near-identical answers across runs, the decoding-only CI narrows significantly compared to method 1). A and B still overlap here (correctly), but C at least should outperform A in a statistically significant manner more often. The method has not cheated mathematically, BUT it is misrepresenting decoding noise as variation in the models’ ability to answer questions in the language/domain.
Method 3): run-bootstrap with SE / √B. Now what do you do if you want to be EXTRA sure your failed finetuning would still look decent? Same resampling as method 2), but instead of calculating the bootstrapped standard error as standard deviation of the 30 observed accuracies, we further divide it by √B (B=30), as though the 30 bootstrap replicates were 30 independent runs, inflating the test statistics by \(\sqrt{30}\). The CI drops to ±0.1X, about 10x tighter than method 1). The procedure declares the failed finetuned model B significantly better than A. If you glance at it, you may conclude the method can resolve differences at a fraction-of-a-percentage-point scale, but the apparent precision is a product of a fabrication, not of the data.
The Honest Fix: Paired Question-Bootstrap
The three bootstrap methods above span the range from “honest but blunt” (question-bootstrap on single-model accuracy) to “conceptually wrong and badly miscalibrated” (run-bootstrap /√B, fake precision). Methods 2) and 3) answer the wrong question entirely; they quantify decoding noise on the exact same 4,000 questions, not the uncertainty we actually care about, which is “would this model still win on a different 4,000-question sample from the same domain?”
The fix is to bootstrap the right object: per-question paired differences. For each question \(q\), compute \(d_q = \bar{y}_q - \bar{x}_q\) (the 8-run mean difference between the finetuned model and the base). Then resample the \(d_q\) values with replacement to build the CI on the mean difference. This is the paired question-bootstrap. It resamples questions, capturing question-sampling variability, while preserving pairing to control for question difficulty. It answers exactly if we drew a different benchmark from the same distribution, would the finetuned model still outperform the base.
Two things conspire to make this powerful despite its honest width. First, ~70% of questions sit in the shared easy/hard buckets where both models answer identically on every run, so \(d_q = 0\) exactly and contributes zero variance; pairing annihilates the common difficulty signal instead of carrying it around. Second, on the ~30% of middle questions where decoding noise actually lives, each \(d_q\) already averages 8 runs, so its variance shrinks by a factor of \(N_{\text{runs}}\) before it even enters the bootstrap. Combined with the \(\sqrt{N_{\text{questions}}}\) shrinkage from the law of large numbers over 4,000 resampled questions, this tightens the CI to around ±0.4–0.5pp. This is essentially the bootstrap analog of the paired t-test on per-question differences \(d_q\), and both converge to the same answer asymptotically.
Code
def paired_question_bootstrap(s_x: np.ndarray, s_y: np.ndarray, rng: np.random.Generator, n_boot: int=2000) ->dict:"""Paired question-bootstrap: resample per-question differences d_q with replacement. Captures question-sampling variability while preserving pairing.""" d_per_q = s_y.mean(axis=0) - s_x.mean(axis=0) n =len(d_per_q) obs_diff = d_per_q.mean() idx = rng.integers(0, n, size=(n_boot, n)) boot_diffs = d_per_q[idx].mean(axis=1) se = boot_diffs.std(ddof=1) ci95 = Z * se *100return {"diff": obs_diff *100, "se": se *100, "ci95": ci95,"z": obs_diff / se if se >0else0.0,"p": 2* (1- stats.norm.cdf(abs(obs_diff / se))) if se >0else1.0}rows = []boot_rng = np.random.default_rng(SEED +77)for label, x, y in [("A vs B (true diff = 0)", scores["A"], scores["B"]), ("A vs C (true diff = +1pp)", scores["A"], scores["C"])]: r = paired_question_bootstrap(x, y, boot_rng) rows.append({"comparison": label,"obs diff": f"{r['diff']:+.2f}pp","95% CI on diff": f"±{r['ci95']:.2f}pp","z": f"{r['z']:.2f}","p-value": f"{r['p']:.4f}", })pd.DataFrame(rows)
comparison
obs diff
95% CI on diff
z
p-value
0
A vs B (true diff = 0)
-0.01pp
±0.39pp
-0.05
0.9628
1
A vs C (true diff = +1pp)
+1.17pp
±0.51pp
4.48
0.0000
For comparison, the paired t-test on the same per-question differences \(d_q\) gives nearly identical results, since bootstrapping the mean converges to the Central Limit Theorem (CLT):
Code
def paired_t_over_runs(s_x: np.ndarray, s_y: np.ndarray) ->dict:"""Paired t-test on per-question mean scores across N_RUNS runs.""" d_per_q = s_y.mean(axis=0) - s_x.mean(axis=0) n =len(d_per_q) df = n -1 diff = d_per_q.mean() *100 se = d_per_q.std(ddof=1) / np.sqrt(n) *100 t_stat = diff / se if se >0else0.0 p =2* (1- stats.t.cdf(abs(t_stat), df=df)) t_crit = stats.t.ppf(1-0.05/2, df=df)return {"diff": diff, "se": se, "ci95": t_crit * se, "t": t_stat, "df": df, "p": p}rows = []for label, x, y in [("A vs B (true diff = 0)", scores["A"], scores["B"]), ("A vs C (true diff = +1pp)", scores["A"], scores["C"])]: r = paired_t_over_runs(x, y) rows.append({"comparison": label,"obs diff": f"{r['diff']:+.2f}pp","95% CI on diff": f"±{r['ci95']:.2f}pp","t": f"{r['t']:.2f}","p-value": f"{r['p']:.4f}", })pd.DataFrame(rows)
comparison
obs diff
95% CI on diff
t
p-value
0
A vs B (true diff = 0)
-0.01pp
±0.40pp
-0.05
0.9635
1
A vs C (true diff = +1pp)
+1.17pp
±0.52pp
4.43
0.0000
The two methods agree because they operate on the same object (\(d_q\)) and differ only in how they estimate SE: one uses the CLT directly, the other uses resampling. Both answer the question-sampling question honestly. The paired t-test is the parametric shortcut; the paired question-bootstrap is its nonparametric twin.
Would more independent runs work? Running 30 real decoding seeds per model on the same 4,000 questions gives a tighter CI on decoding noise, but it still only tells you about these exact 4,000 questions. It answers is the observed difference on this benchmark reproducible across decoding seeds? rather than would this model win on a different benchmark from the same domain?. For the claim most localizers are making, our finetune is better at Thai/medical/finance/whatever domain, you need question-sampling uncertainty, not decoding-noise uncertainty. To demonstrate this, we ran 100 independent decoding runs of a localization effort’s finetuned model and its base model on the same benchmark suite used in their official evaluation, which reports 8 runs with 30 bootstrap replicates, aka Method 3) above. The 100-run CIs on overall accuracy are ±0.07pp (finetuned) and ±0.12pp (base). This is in-line with their officially reported CIs over 30 runs.
Code
empirical_df = pd.read_csv("../../data/benchmaxxing/bigon_summary.csv")# Overall scores from 100 independent runsoverall = empirical_df[empirical_df["level"] =="overall"]comp = empirical_df[(empirical_df["level"] =="competency")]print("=== 100 Independent Runs: Overall Thai Score ===\n")for _, row in overall.iterrows(): model_label ="Finetuned"if row["model"] =="bigon"else"Base (Qwen)"print(f" {model_label}: {row['mean']:.2f}% ± {row['ci95_half_width']:.2f}pp "f"(sd={row['sd_across_runs']:.2f}pp over {int(row['n_runs'])} runs)")bigon_overall = overall[overall["model"] =="bigon"].iloc[0]qwen_overall = overall[overall["model"] =="qwen"].iloc[0]diff = bigon_overall["mean"] - qwen_overall["mean"]# SE of difference (independent runs)se_diff = np.sqrt(bigon_overall["se"]**2+ qwen_overall["se"]**2)print(f"\n Observed difference: +{diff:.2f}pp")print(f" SE of difference (100 runs each): ±{Z * se_diff:.2f}pp")print(f"\n=== Per-Competency SD across 100 Runs ===\n")for _, row in comp.sort_values("sd_across_runs", ascending=False).iterrows(): model_label ="Finetuned"if row["model"] =="bigon"else"Base"print(f" {model_label} | {row['name']:25s} sd={row['sd_across_runs']:.2f}pp, "f"95% CI=±{row['ci95_half_width']:.2f}pp")
=== 100 Independent Runs: Overall Thai Score ===
Finetuned: 61.21% ± 0.07pp (sd=0.35pp over 100 runs)
Base (Qwen): 59.10% ± 0.12pp (sd=0.60pp over 100 runs)
Observed difference: +2.11pp
SE of difference (100 runs each): ±0.14pp
=== Per-Competency SD across 100 Runs ===
Base | safety sd=2.58pp, 95% CI=±0.51pp
Base | instruction-following sd=2.20pp, 95% CI=±0.44pp
Finetuned | instruction-following sd=1.88pp, 95% CI=±0.37pp
Base | knowledge sd=1.61pp, 95% CI=±0.32pp
Base | nlr sd=0.94pp, 95% CI=±0.19pp
Base | nlu sd=0.64pp, 95% CI=±0.13pp
Finetuned | safety sd=0.51pp, 95% CI=±0.10pp
Finetuned | knowledge sd=0.45pp, 95% CI=±0.09pp
Finetuned | nlr sd=0.26pp, 95% CI=±0.05pp
Finetuned | nlu sd=0.23pp, 95% CI=±0.05pp
Finetuned | nlg sd=0.17pp, 95% CI=±0.03pp
Base | nlg sd=0.17pp, 95% CI=±0.03pp
Any bootstrap method that claims tighter CIs than the paired question-bootstrap on an 8-run dataset is not finding extra information; it is either answering a narrower question (decoding noise on these exact questions, as with method (2)), or simply miscalibrated (as with method (3)). The calibration section below confirms this with 2000 simulated benchmarks.
Calibration: Power and False Positive across 2000 Runs
To judge whether each method is actually honest, we measure its false-positive rate and its power across 2000 hypothetical benchmarks. In each, B is an exact copy of A (true difference = 0, used to measure false positive) and C has a +1pp true uplift (used to measure power).
The calibration table turns the earlier these-bars-look-too-narrow intuition into a concrete indictment. Method 3), run-bootstrap with /√B rejects the null at over 40% when the two models are truly identical. If we run it on a finetuned model with zero real improvement and repeat the experiment 100 times with fresh decoding seeds, you will declare “significant uplift over base model” in more than 40 of them. This is not a subtle bias; the test is actively making up differences that are not there. Once fixed in Method 2), the CI becomes too conservative and power significantly drops to the level of a single-run McNemar’s test (~44%).
Method 1) unpaired question-bootstrap resamples A’s and C’s per-question scores with independent question indices, destroying the pairing. The bimodal between-question variance (easy-vs-hard buckets) is carried into the difference on both sides instead of cancelling, producing a CI wider than the 1pp signal. That is why it has near-zero power despite being conceptually “correct” bootstrap. Tt is doing the right resampling but breaking the pairing that makes the signal visible.
The paired question-bootstrap and paired t-test answer the same question honestly AND powerfully. Both resample (or compute SE over) the per-question differences \(d_q = \bar{y}_q - \bar{x}_q\), so shared easy/hard questions contribute zero variance and pairing annihilates the common difficulty signal. They deliver ~5% false positive rate (well-calibrated) and near-100% power to detect a 1pp uplift on the same 4,000-question, 8-run dataset.
More Obvious Concerns: Multiple Comparisons and Aggregation
Even if the hypothesis test is honestly specified, two further traps can manufacture a headline uplift out of thin air. Both are worth naming because they travel under the same cover of “we followed best practice”.
Multiple Comparisons A typical localization benchmark reports accuracy across many slices: languages, subtasks, domains, prompt formats, and so on. If each slice is tested at \(\alpha = 0.05\) independently, the family-wise probability of at least one false positive is \(1 - (1 - 0.05)^k\); as few as k=5 will return at least one false positive 22.6% of the time. The fix is standard: apply Bonferroni (\(\alpha / k\)) or Holm-Bonferroni if you want more power, or Benjamini-Hochberg if you are willing to control false discovery rate instead of family-wise error.
Selective Aggregation Suppose a finetuned model is evaluated on 5 languages: English, Mandarin, Japanese, Korean, and Burmese. The base model already handles the four major languages well and the finetuned one makes no real difference on them. But the finetuned model sees a +5pp uplift on Burmese, a small low-resource language with a 200-example test set. The macro-averaged score across the 5 languages is then +1pp, which sounds like a broad win. Under a micro-average (pooling all questions), the ~200 Burmese examples out of a weighted total are even more diluted and the headline reverses to ~0pp. Neither number tells the real story, which is “the finetuning helps on Burmese, does nothing elsewhere, and the Burmese evaluation set is too small to resolve 5pp anyway”.
The deception works in both directions. Macro-average lets a single narrow slice carry the narrative; micro-average does the opposite when the improvement is concentrated in one large slice. An honest report states 1) the per-slice effect with its own CI and multiple-comparison correction, 2) the aggregated effect with the weighting scheme specified, and 3) which slices drive the aggregate. If a paper claims “+1pp macro-average” without the per-slice breakdown, assume the aggregate is hiding something until shown otherwise.
Large corporations can afford a few million USD of extremely-high-upside, low-probability investments that a small nation cannot. For instance, Walmart’s annual revenue of 713 billion USD in 2025 is 1.2x times Thailand’s GDP. Unfortunately, small nations like Thailand are often the place where government investments are greenlit by the statistical hocus pocus mentioned in this article. I believe the Bike-shed Effect plays an important role. The concept was satirically proposed by Cyril Northcote Parkinson in 1957. He gave an example of a fictional committee whose job was to approve the plans for a nuclear power plant. He posited that they would spend most of their time debating minor but easy-to-understand issues such as what color the bike shed should be, and little on the more important but complex topics such as the systems of the power plant itself. For most government grant committees, or dare I say academic reviewers these days, the nuances of how confidence intervals are derived are akin to the nuclear reactor’s cooling system; technically critical, but opaque and easy to nod along to. What gets the attention instead is the bike shed: a clean bar chart with non-overlapping error bars, a round number like “2.3% uplift over base model”, a story about national AI sovereignty. Reviewers read the headline, check that the CI does not cross zero, and move on. Nobody asks whether the CI came from resampling decoding seeds or questions, let alone whether an extra \(\sqrt{30}\) was slipped into the denominator along the way.
The asymmetry is brutal. A team that spends six months building a finetune and papering over its 0.5pp uplift with bootstrap shenanigans walks out with a multi-million-dollar grant; a reviewer who flags the \(\sqrt{B}\) misuse spends two hours explaining it, gets labeled “difficult”, and gets dropped from the next panel. The incentives point in exactly one direction, and so do the grants.
This is not really a statistics problem; the statistics have been sorted for decades. McNemar’s test (1947), bootstrap (1979), Paired t-tests (1908) are all part of undergraduate-level statistics classes. What is missing is a review culture that treats these tools as load-bearing rather than decorative, and a willingness to say “your 1pp uplift is within the CI of a well-specified test” without the conversation ending there. Until then, the bike shed gets painted on schedule, the reactor keeps leaking, and the taxpayers pay for both.
Appendix
To give more contexts on WangchanBERTa, we DID claim that “our model wangchanberta-baseatt-spm-uncased trained on the 78.5GB dataset outperforms strong baselines (NBSVM, CRF and ULMFit) and multi-lingual models (XLMR and mBERT) on both sequence classification and token classification tasks in human-annotated, mono-lingual context”, and specifically “outperfroms both strong baselines and other transformer-based architecture on all downstream tasks except Generated Reviews (EN-TH)” and “achieves the highest micro-averaged F1 score in all tasks except POS tagging in ThaiNER dataset”. In hindsight, I would have worded it much more carefully; you live and you learn. Nonetheless, these were task-level descriptions of the empirical results. Unlike some of these recent localizers, we DID NOT use random aggregation magic across 1,000-example or even 100-example test sets to claim to be “the top performing model overall on XX domain”. Our test sets were also reasonably sized, smallest at 621 and largest at 17,453, whereas median is about 5,000 examples, so a McNemar’s or paired t/z-test might also give confidence intervals that arrive at the same conclusion as the point estimates anyways. And last but most importantly, we DID NOT ask for millions of USD in funding off of 1% uplifts in point estimates.
Exceptions are sovereign AI labs who DO train foundational models such as G42 and TII.
This may seem outdated for LLM evaluation but since these localization projects are only interested in adapting to a new language/domain, they treat more advanced capabilities like guardrails rather than objectives and focus on more traditional benchmarks such as MMLU.
The hand-rolled McNemar’s z-test used in the main text is algebraically equivalent to the canonical chi-squared version without continuity correction: \(z^2 = \chi^2\) and the two-sided p-values match exactly. Quick sanity check against statsmodels.stats.contingency_tables.mcnemar:
Code
from statsmodels.stats.contingency_tables import mcnemar as sm_mcnemarsanity_rows = []for label, x, y in [("A vs B", a0, b0), ("A vs C", a0, c0)]: r = mcnemar_test(x, y)# statsmodels expects the 2x2 contingency table:# y=0 y=1# x=0 [ n00 , n01 ]# x=1 [ n10 , n11 ] n00 =int(((x ==0) & (y ==0)).sum()) n11 =int(((x ==1) & (y ==1)).sum()) sm = sm_mcnemar([[n00, r["n01"]], [r["n10"], n11]], exact=False, correction=False) sanity_rows.append({"comparison": label,"hand z²": f"{r['z']**2:.4f}","statsmodels χ²": f"{sm.statistic:.4f}","hand p": f"{r['p']:.6f}","statsmodels p": f"{sm.pvalue:.6f}", })pd.DataFrame(sanity_rows)
comparison
hand z²
statsmodels χ²
hand p
statsmodels p
0
A vs B
2.6896
2.6896
0.101006
0.101006
1
A vs C
12.0071
12.0071
0.000530
0.000530
The z-form is preferred in the main text because we also need a directional SE on the accuracy difference to build the CIs plotted in the figures. Chi-squared gives only a non-negative test statistic with no natural SE attached, so we would end up recomputing \(\sqrt{n_{01} + n_{10}}/n\) by hand anyway.
You may notice that the per-run standard deviations printed for A, B, and C in the display-seed setup cell come out visibly different, despite A and B being structurally identical. This is a sampling artifact of estimating a standard deviation from only 8 observations, not a property of the models. The true per-run standard deviation is the same for all three models because it only depends on the distribution of \(p_q\), and C’s derivation only swaps a 1% fraction of p_q = 0 questions to p_q = 1, both of which contribute zero variance.
Code
# True per-run standard deviation: sqrt(sum_q p_q(1-p_q)) / ntrue_stdev_A = np.sqrt((p_A_d * (1- p_A_d)).sum()) / N_QUESTIONS *100true_stdev_B = np.sqrt((p_B_d * (1- p_B_d)).sum()) / N_QUESTIONS *100true_stdev_C = np.sqrt((p_C_d * (1- p_C_d)).sum()) / N_QUESTIONS *100print(f"True per-run stdev A: {true_stdev_A:.4f}pp")print(f"True per-run stdev B: {true_stdev_B:.4f}pp")print(f"True per-run stdev C: {true_stdev_C:.4f}pp")# Empirical 5-95% range of sample stdev at n=8, from 200 fresh 8-run replications of Asample_stdevs = []for trial inrange(200): s = (np.random.default_rng(DISPLAY_SEED +9000+ trial).random((N_RUNS, N_QUESTIONS)) < p_A_d).astype(int) sample_stdevs.append(s.mean(axis=1).std(ddof=1) *100)sample_stdevs = np.array(sample_stdevs)print(f"\nSample stdev at n={N_RUNS} (200 replications of A):")print(f" median={np.median(sample_stdevs):.3f}pp, "f"5–95% range=[{np.percentile(sample_stdevs, 5):.3f}, {np.percentile(sample_stdevs, 95):.3f}]pp")
At \(n=8\) the sample standard deviation has a coefficient of variation of roughly \(1 / \sqrt{2(n-1)} \approx 0.27\), so any single 8-run evaluation will produce a sample standard deviation anywhere in a fairly wide band around the true value. Reading meaningful differences into the standard deviations of A, B, and C under this kind of sample size is itself a small benchmaxxing trap worth avoiding.